In my previous posts about the
two Bitdefender bugs related to 7z, I explicitly
mentioned that Igor Pavlov’s 7-Zip reference implementation was not affected.
Unfortunately, I cannot do the same for the bugs described in this blog post.
I found these bugs in a prominent antivirus product and then realized that 7-Zip itself was affected.
As the antivirus vendor has not yet published a patch, I will add the name of the affected product in
an update to this post as soon as this happens.
Since Igor Pavlov has already published a patched version of 7-Zip and exploitation is likely to be easier for 7-Zip,
I figured it would be best to publish this post as soon as possible.
UPDATE (2018-06-05): The antivirus vendor I was talking about was F-Secure.
Introduction
In the following, I will outline two bugs that affect 7-Zip before version 18.00 as well as p7zip.
The first one (RAR PPMd) is the more critical and the more involved one.
The second one (ZIP Shrink) seems to be less critical, but also much easier to understand.
Memory Corruptions via RAR PPMd (CVE-2018-5996)
7-Zip’s RAR code is mostly based on a recent UnRAR version. For version 3 of the RAR format, PPMd can be used, which
is an implementation of the PPMII compression algorithm by Dmitry Shkarin. If you want to learn more about the details
of PPMd and PPMII, I’d recommend Shkarin’s paper PPM: one step to practicality.
Interestingly, the 7z archive format can be used with PPMd as well, and 7-Zip uses the same code that is used for RAR3.
As a matter of fact, this is the very PPMd implementation that was used by Bitdefender in a way that caused a
stack based buffer overflow.
In essence, this bug is due to improper exception handling in 7-Zip’s RAR3 handler. In particular, one might argue that
it is not a bug in the PPMd code itself or in UnRAR’s extraction code.
The Bug
The RAR handler has a function NArchive::NRar::CHandler::Extract containing a loop that looks roughly as follows (heavily simplified!):
for (unsigned i = 0;; i++, /*OMITTED: unpack size updates*/) {
//OMITTED: retrieve i-th item and setup input stream
CMyComPtr<ICompressCoder> commonCoder;
switch (item.Method) {
case '0':
{
commonCoder = copyCoder;
break;
}
case '1':
case '2':
case '3':
case '4':
case '5':
{
unsigned m;
for (m = 0; m < methodItems.Size(); m++)
if (methodItems[m].RarUnPackVersion == item.UnPackVersion) { break; }
if (m == methodItems.Size()) { m = methodItems.Add(CreateCoder(/*OMITTED*/)); }
//OMITTED: solidness check
commonCoder = methodItems[m].Coder;
break;
}
default:
outStream.Release();
RINOK(extractCallback->SetOperationResult(NExtract::NOperationResult::kUnsupportedMethod));
continue;
}
HRESULT result = commonCoder->Code(inStream, outStream, &packSize, &outSize, progress);
//OMITTED: encryptedness, outsize and crc check
outStream.Release();
if (result != S_OK) {
if (result == S_FALSE) { opRes = NExtract::NOperationResult::kDataError; }
else if (result == E_NOTIMPL) { opRes = NExtract::NOperationResult::kUnsupportedMethod; }
else { return result; }
}
RINOK(extractCallback->SetOperationResult(opRes));
}
The important bit about this function is essentially that at most one coder is created for each RAR unpack version.
If an archive contains multiple items that are compressed with the same RAR unpack version,
those will be decoded with the same coder object.
Observe, moreover, that a call to the Code method can fail, returning the result S_FALSE,
and the created coder will be reused for the next item anyway, given that the callback function does not catch this (it does not).
So let us see where the error code S_FALSE may come from.
The method NCompress::NRar3::CDecoder::Code
looks as follows (again simplified):
STDMETHODIMP CDecoder::Code(ISequentialInStream *inStream, ISequentialOutStream *outStream,
const UInt64 *inSize, const UInt64 *outSize, ICompressProgressInfo *progress) {
try {
if (!inSize) { return E_INVALIDARG; }
//OMITTED: allocate and initialize VM, window and bitdecoder
_outStream = outStream;
_unpackSize = outSize ? *outSize : (UInt64)(Int64)-1;
return CodeReal(progress);
}
catch(const CInBufferException &e) { return e.ErrorCode; }
catch(...) { return S_FALSE; }
}
The CInBufferException is interesting. As the name suggests, this exception may be
thrown while reading from the input stream.
It is not completely straightforward, but nevertheless easily possible to
trigger the exception with a RAR3 archive item
such that the error code is S_FALSE.
I will leave it as an exercise for the interested
reader to figure out the details of how this can be achieved.
Why is this interesting? Well, because in
case RAR3 with PPMd is used this exception may be thrown in the middle of an update
of the PPMd model, putting the soundness of the model state at risk.
Recall that the same coder will be used for the next item even after
a CInBufferException with error code S_FALSE has been thrown.
Note, moreover, that the RAR3 decoder holds the PPMd model state. A brief look at the method
NCompress::NRar3::CDecoder::InitPPM reveals the fact that this model state
is only reinitialized if an item explicitly requests it.
This is a feature that allows to keep the same model with the collected probability heuristics between different items.
But it also means that we can do the following:
- Construct the first item of a RAR3 archive such that a
CInBufferException with error code S_FALSE is thrown
in the middle of a PPMd model update. Essentially, this means that we can let an arbitrary call to the Decode method
of the range decoder used in Ppmd7_DecodeSymbol fail, jumping out of the PPMd code.
- The subsequent item of the archive does not have the
reset bit set that would cause the model to be reinitialized.
Hence, the PPMd code will operate on a potentially broken model state.
So far this may not look too bad. In order to understand how this bug can be turned into attacker controlled
memory corruptions, we need to understand a little bit more about the PPMd model state and how it is updated.
PPMd Preliminaries
The main idea of all PPM compression algorithms is to build a Markov model of some finite order D.
In the PPMd implementation, the model state is essentially a 256-ary context tree of maximum depth D, in which the path from the root to the
current context node is to be interpreted as a sequence of byte symbols.
In particular, the parent relation is to be understood as a suffix relation.
Additionally, every context node stores frequency statistics about possible successor symbols connected
with a successor context node.
A context node is of type CPpmd7_Context, defined as follows:
typedef struct CPpmd7_Context_ {
UInt16 NumStats;
UInt16 SummFreq;
CPpmd_State_Ref Stats;
CPpmd7_Context_Ref Suffix;
} CPpmd7_Context;
The field NumStats holds the number of elements the Stats array contains.
The type CPpmd_State is defined as follows:
typedef struct {
Byte Symbol;
Byte Freq;
UInt16 SuccessorLow;
UInt16 SuccessorHigh;
} CPpmd_State;
So far, so good. Now what about the model update? I will spare you the details, describing only abstractly
how a new symbol is decoded:
- When
Ppmd7_DecodeSymbol is called, the current context is p->MinContext, which is equal to p->MaxContext,
assuming a sound model state.
- A threshold value is read from the range decoder. This value is used to find a corresponding symbol in the
Stats
array of the current context p->MinContext.
- If no corresponding symbol can be found,
p->MinContext is moved upwards
the tree (following the suffix links) until a context with (strictly) larger Stats array is found.
Then, a new threshold is read and used to find a corresponding value in the current Stats array,
ignoring the symbols of the contexts that have been previously visited.
This process is repeated until a value is found.
- Finally, the ranger decoder’s
decode method is called, the found state is written to p->FoundState,
and one of the Ppmd7_Update functions is called to update the model. As a part of this process,
the UpdateModel function adds the found symbol to the Stats array of each context between
p->MaxContext and p->MinContext (exclusively).
One of the key invariants the update mechanism tries to establish is that the Stats array of every context
contains each of the 256 symbols at most once. However, this property only follows inductively,
since there is no explicit duplicate check when a new symbol is inserted. With the bug described above,
it is easy to see how we can add duplicate symbols to Stats arrays:
- The first RAR3 item is created such that a few context nodes are created, and the function
Ppmd7_DecodeSymbol then moves
p->MinContext upwards the tree at least once, until the corresponding symbol is found. Then, the subsequent
call to the range decoders decode method fails with a CInBufferException.
- The next RAR3 item does not have the
reset bit set, so that we can continue with the previously
created PPMd model.
- The
Ppmd7_DecodeSymbol function is entered with a fresh range decoder and p->MinContext != p->MaxContext.
It finds the corresponding symbol immediately in p->MinContext. However, this symbol may now be one that already occurs
in the contexts between p->MaxContext and p->MinContext.
When the UpdateModel function is called, this symbol is added as a duplicate to the Stats array to each
context between p->MaxContext and p->MinContext (exclusively).
Okay, so now we know how to add duplicate symbols into the Stats array.
Let us see how we can make use of this to cause an actual memory corruption.
Triggering a Stack Buffer Overflow
The following code is run as a part of Ppmd7_DecodeSymbol to move the p->MinContext pointer upwards
the context tree:
CPpmd_State *ps[256];
unsigned numMasked = p->MinContext->NumStats;
do {
p->OrderFall++;
if (!p->MinContext->Suffix) { return -1; }
p->MinContext = Ppmd7_GetContext(p, p->MinContext->Suffix);
} while (p->MinContext->NumStats == numMasked);
UInt32 hiCnt = 0;
CPpmd_State *s = Ppmd7_GetStats(p, p->MinContext);
unsigned i = 0;
unsigned num = p->MinContext->NumStats - numMasked;
do {
int k = (int)(MASK(s->Symbol));
hiCnt += (s->Freq & k);
ps[i] = s++;
i -= k;
} while (i != num);
MASK is a macro that accesses a byte array which holds the value 0x00 at the index of each masked symbol,
and the value 0xFF otherwise. Clearly, the intention is to fill the stack buffer ps with pointers to all unmasked
symbol states.
Observe that the stack buffer ps has a fixed size of 256 and there is no overflow check.
This means that if the Stats array contains a masked symbol multiple times, we can access the array out of bound
and overflow the ps buffer.
Usually, such out of bound buffer reads make exploitation very difficult,
because one cannot easily control the memory that is read.
However, this is no issue in the case of PPMd, because the implementation allocates only one large pool on the heap,
and then makes use of its own memory allocator to allocate all context and state structs within
this pool. This ensures very quick allocation and a low memory usage, but it also allows an attacker to control the out
of bound read to structures within this pool very reliably and independently of the system’s heap implementation.
For example, the first RAR3 item can be constructed such that the pool is filled with the desired data, avoiding
uninitialized out of bound reads.
Finally, note that the attacker can overflow the stack buffer with pointers to data that is highly attacker controlled itself.
Triggering a Heap Buffer Overflow
Building on the previous section, we now want to corrupt the heap.
Perhaps not surprisingly, it is also possible to read the Stats array out of bound
without overflowing the stack buffer ps.
This allows us to let s point to a CPpmd_State with attacker controlled data.
Since p->FoundState may be one of the ps states and the model updating process assumes that the Stats array
of p->MinContext as well as its suffix contexts contain the symbol p->FoundState->Symbol.
This code fragment is part of the function UpdateModel:
do { s++; } while (s->Symbol != p->FoundState->Symbol);
if (s[0].Freq >= s[-1].Freq) {
SwapStates(&s[0], &s[-1]);
s--;
}
Again, there is no bound check on the Stats array, so the pointer s can be moved easily over the end of the allocated heap buffer.
Optimally, we would construct our input such that s is out of bound and s-1 within the allocated pool, allowing an attacker controlled heap corruption.
On Attacker Control, Exploitation and Mitigation
The 7-Zip binaries for Windows are shipped with neither the /NXCOMPAT nor the /DYNAMICBASE flags.
This means effectively that 7-Zip runs without ASLR on all Windows systems, and DEP is only enabled on Windows x64 or on Windows 10 x86.
For example, the following screenshot shows the most recent 7-Zip 18.00 running on a fully updated Windows 8.1 x86:
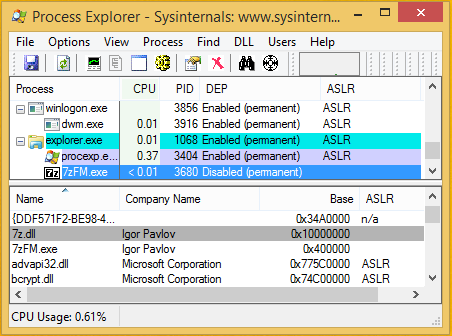
Moreover, 7-Zip is compiled without /GS flag, so there are no stack canaries.
Since there are various ways to corrupt the stack and the heap in highly attacker controlled ways, exploitation for
remote code execution is straightforward, especially if no DEP is used.
I have discussed this issue with Igor Pavlov and tried to convince him to enable all three flags. However, he
refused to enable /DYNAMICBASE because he prefers to ship the binaries without relocation table to achieve a minimal binary size.
Moreover, he doesn’t want to enable /GS, because it could affect the runtime as well as the binary size. At least he will try to enable
/NXCOMPAT for the next release. Apparently, it is currently not enabled because 7-Zip is linked with an obsolete linker
that doesn’t support the flag.
Conclusion
The outlined heap and stack memory corruptions are only scratching the surface of possible exploitation paths.
Most likely there are many other and possibly even neater ways of causing memory corruptions in an attacker
controlled fashion.
This bug demonstrates again how difficult it can be to integrate external code into an existing code base.
In particular, handling exceptions correctly and understanding the control flow they induce can be challenging.
In the post about Bitdefender’s PPMd stack buffer overflow, I
already made clear that the PPMd code is very fragile.
A slight misuse of its API, or a tiny mistake while integrating it into another code base may lead to multiple
dangerous memory corruptions.
If you use Shkarin’s PPMd implementation, I would strongly recommend you to harden it by adding out of bound checks wherever possible,
and to make sure the basic model invariants always hold. Moreover, in case exceptions are used, one could add an additional error
flag to the model that is set to true before updating the model, and only set to false after the update has been successfully completed.
This should significantly mitigate the danger of corrupting the model state.
Do you have any comments, feedback, doubts, or complaints? I would love to hear them. You can find my e-mail address on the about page.
Alternatively, you are invited to join the discussion on HackerNews or on /r/netsec.
Timeline of Disclosure
- 2018-01-06 - Discovery
- 2018-01-06 - Report
- 2018-01-10 - Patched version 7-Zip 18.00 (beta) released
- 2018-01-22 - MITRE assigned CVE-2018-5996
ZIP Shrink: Heap Buffer Overflow (CVE-2017-17969)
Let us proceed by discussing the other bug, which concerns ZIP Shrink. Shrink is an implementation of the Lempel-Ziv-Welch (LZW) compression algorithm. It has been used by PKWARE’s PKZIP
before version 2.0, which was released in 1993 (sic!). In fact, shrink is so old and so rarely used, that already in 2005,
when Igor Pavlov wrote 7-Zip’s shrink decoder, he had a hard time finding sample archives to test the code.
In essence, shrink is LZW with a dynamic code size between 9 and 13 bits, and a
special feature that allows to partially clear the dictionary.
7-Zip’s shrink decoder is quite straightforward and easy to understand. In fact, it consists of only 200 lines of code.
Nevertheless, it contains a buffer overflow bug.
The Bug
The shrink model’s state essentially only consists of the two arrays _parents and _suffixes, which store the
LZW dictionary in a space efficient way. Moreover, there is a buffer _stack to which the current sequence is written:
UInt16 _parents[kNumItems];
Byte _suffixes[kNumItems];
Byte _stack[kNumItems];
The following code fragment is part of the method NCompress::NShrink::CDecoder::CodeReal:
unsigned cur = sym;
unsigned i = 0;
while (cur >= 256) {
_stack[i++] = _suffixes[cur];
cur = _parents[cur];
}
Observe that there is no bound check on the value of i.
One way this can be exploited to overflow
the heap buffer _stack is by constructing a symbol of sequence such that the _parents array forms a cycle.
This is possible, because the decoder only ensures that a parent node does not link to itself (cycle of length one).
Interestingly, the old versions of PKZIP create shrink archives that may contain such self-linked parents, so a compatible
implementation should actually accept this (7-Zip 18.00 fixes this).
Moreover, using the special symbol sequence 256,2 one can clear parent nodes in an attacker
controlled fashion. A cleared parent node will be set to kNumItems. Since there is no check whether a parent has been
cleared or not, the parents array can be accessed out of bound.
This sounds promising, and it is actually possible to construct archives that make the decoder write attacker controlled data out of bound.
However, I didn’t find an easy way to do so without ending up in an infinite loop. This matters, because the index
i is increased in every iteration of the loop. Hence, an infinite loop will quickly lead to a segmentation fault,
making exploitation for code execution very difficult (if not impossible). However, I didn’t spend too much time on this,
so maybe it is possible to corrupt the heap without entering an infinite loop after all.
Conclusion
It is somewhat surprising that this bug has survived for such a long time in 7-Zip.
I assume this is simply because shrinked ZIP archives are almost non-existent nowadays.
While probably less critical than the RAR PPMd bug, I still found this to be an interesting bug.
In case you have an idea on how to avoid the infinite loop and still corrupt the heap, feel free to shoot me an e-mail.
Timeline of Disclosure
- 2017-12-29 - Discovery
- 2017-12-29 - Report
- 2017-12-29 - MITRE assigned CVE-2017-17969
- 2018-01-10 - Patched version 7-Zip 18.00 (beta) released
Thanks & Acknowledgements
I would like to thank Igor Pavlov for fixing the bugs so quickly.